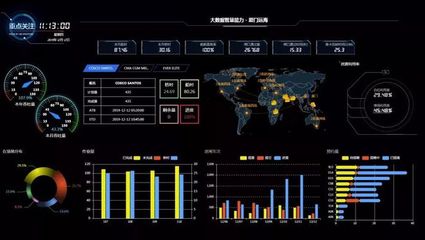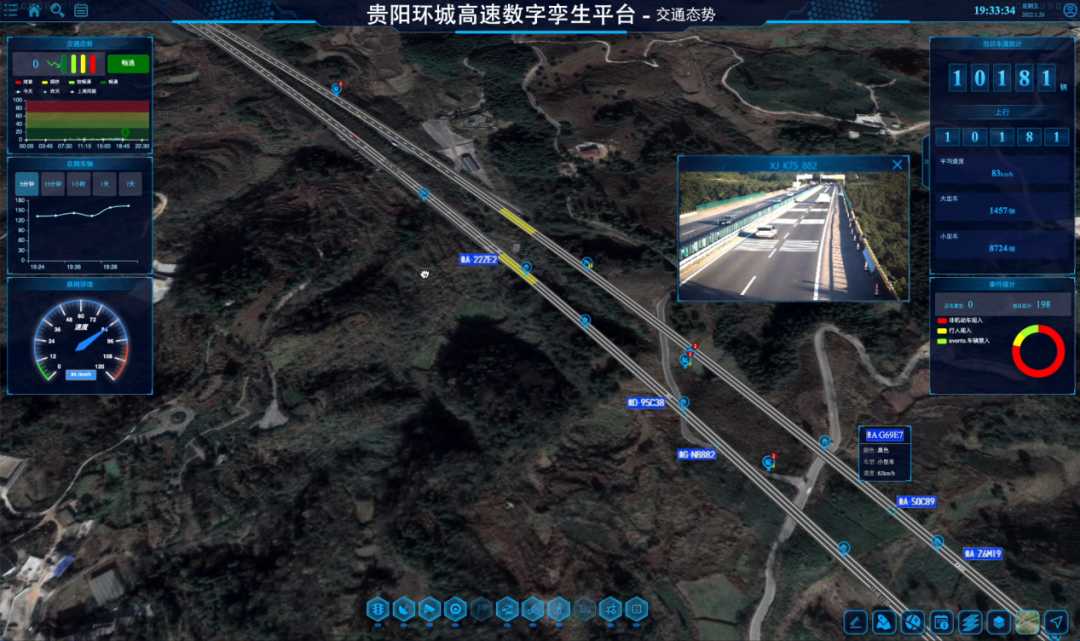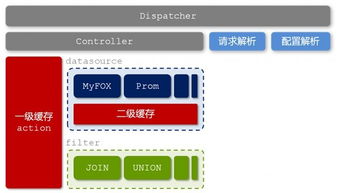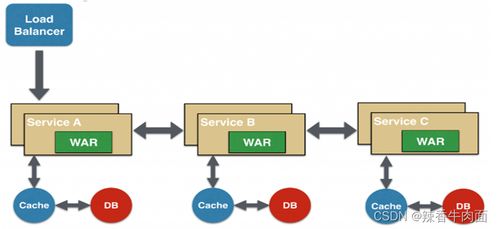
面向服務架構(SOA)作為一種軟件設計模式,通過將應用程序功能劃分為獨立的服務單元,實現了系統的高內聚、低耦合。在數據處理領域,SOA的應用尤為關鍵,它能夠有效提升數據處理的靈活性、可擴展性和復用性。本章將深入探討SOA設計理論在數據處理服務中的實踐應用,涵蓋核心原則、架構設計、實現策略及案例分析。
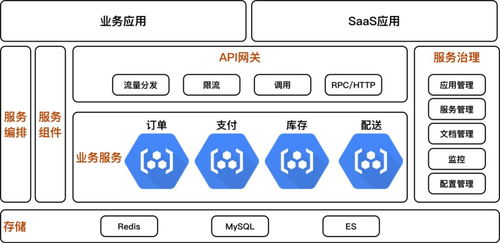
SOA的核心原則包括服務抽象、松散耦合、可復用性和標準化接口。在數據處理服務中,這些原則指導我們構建獨立的數據處理單元,例如數據清洗服務、數據轉換服務或數據聚合服務。每個服務通過定義清晰的接口(如RESTful API或消息隊列)與其他組件交互,確保數據處理流程的模塊化和可維護性。例如,一個電商平臺可能將用戶行為數據分析拆分為多個服務:數據采集服務負責收集日志,數據預處理服務進行格式標準化,而分析服務則生成業務洞察。這種設計不僅簡化了系統復雜性,還允許團隊獨立開發和部署服務。
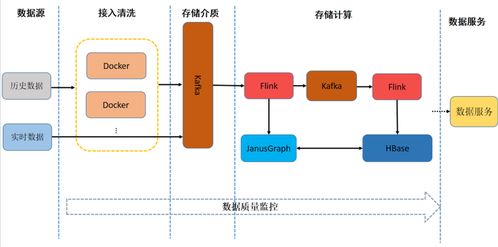
在架構設計層面,數據處理服務常采用分層模型。底層是數據源層,包括數據庫、文件系統或流數據;中間是服務層,由多個微服務組成,每個服務處理特定數據任務;頂層是應用層,通過組合服務實現完整的數據處理流程。實踐中,服務間通信可通過事件驅動架構或API網關實現,確保高效的數據流轉。例如,在金融行業中,風險數據處理服務可能使用事件驅動模式:當交易數據到達時,觸發數據驗證服務,隨后調用計算服務生成風險報告,整個過程通過消息代理(如Kafka)協調,提高了系統的響應速度和可靠性。
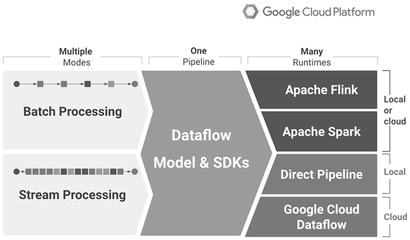
進一步地,實現數據處理服務需考慮技術選型和最佳實踐。常用技術棧包括容器化工具(如Docker和Kubernetes)用于服務部署,數據流框架(如Apache Flink)支持實時處理,以及監控工具(如Prometheus)保障服務健康。設計時應注重數據一致性和錯誤處理機制。例如,在分布式環境中,采用Saga模式管理跨服務事務,避免數據不一致問題。實踐案例中,一家物流公司通過SOA重構其數據處理系統:將包裹追蹤、庫存管理和預測分析拆分為獨立服務,使用REST API進行集成,結果提高了數據處理效率,并降低了維護成本。
SOA在數據處理服務中的優勢包括提升敏捷性和可擴展性,但也面臨挑戰,如服務治理和性能開銷。未來,隨著云原生和AI技術的融合,數據處理服務將更趨向智能化和自動化。通過本章的學習,讀者應能掌握SOA設計理論,并應用于實際數據處理場景,構建高效、可靠的服務化系統。